Quantization guide
Post-training quantization and adjusting sensitivity threshold
Post-training quantization (PTQ) refers to the quantization of a pre-trained model without a model training loop.
To configure post-training quantization using ACE, adjust the quantization_sensitivity_threshold parameter,
which controls the trade-off between accuracy and degree of model compression; this trade-off is illustrated in the diagram below.
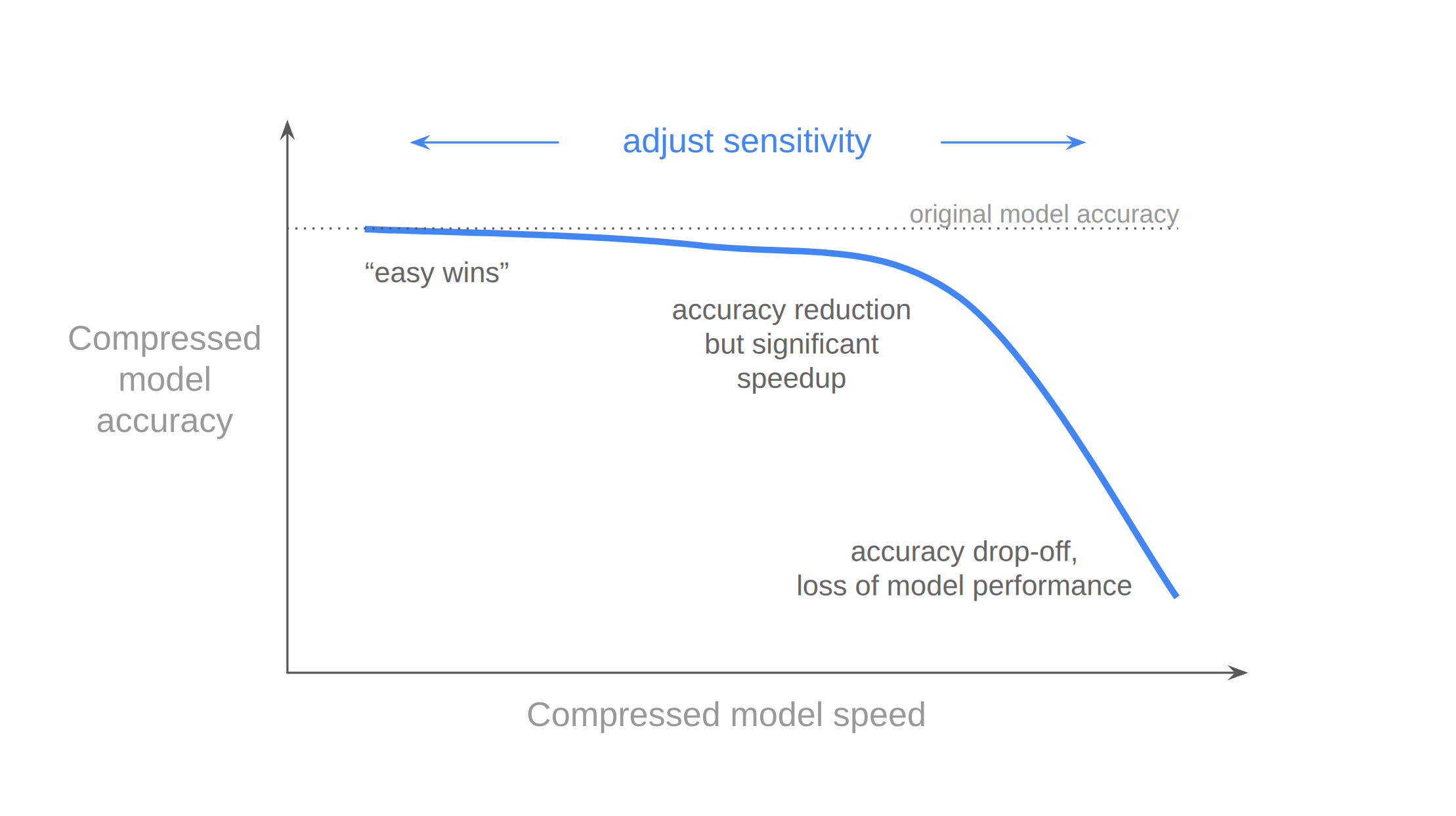
A sensitivity value of 0 will result in clika-ace only applying optimizations that do not affect numerical output of the model.
We recommend starting with a threshold value of 0.005 and modifying the parameter as necessary based on use-case.
Upon completing the compression process, examine the generated logs, which will include a helpful summary table (see output logs example). This table provides guidance for adjusting the threshold based on the desired model compression level.
Be aware that greater compression often impacts model accuracy negatively.
Nevertheless, the model can be subsequently fine-tuned to recover accuracy,
as ClikaModule instances are designed to be compatible with torch.nn.Module.
Quantization-Aware Training
Quantization-aware training (QAT) integrates the quantization process into the model training loop.
Doing so allows the model parameters to adapt as the model precision is reduced, potentially improving
the accuracy of the quantized model.
While the primary recommended entry point to quantization-based compression is through the PTQ feature set of ACE,
quantization-aware training is also a supported SDK feature. As ClikaModule instances are compatible with
the torch.nn.Module interface, the ClikaModule instance can be used in place of the original torch.nn.module
object undergoing fine-tuning. Note that QAT compression workflows are typically slower and require more computational
resources than their PTQ counterparts do.
Quantization sensitivity (QS) is a measurement of the difference between original and quantized outputs of each layer, and is used primarily as a metric to determine which layers should be skipped for quantization. A sensitivity value of 0.0 can be considered to numerical identical to the original layer. On the other hand, 1.0 and above indicate substantially different numerical outputs as compared to the original layer; however, the results are potentially still good depending on the model and architecture in question.